
Orekit supports a large set of data formats natively. For example, leap seconds information can be loaded from file tai-utc.dat provided by USNO or from file UTC-TAI.history provided by IERS. EOP data can be retrieved from weekly Bulletin A, monthly Bulletin B, yearly EOPC04, rapid data finals files. Gravity fields can be loaded from files in EGM, GRGS, ICGEM or SHM formats.
This large number of supported formats is made possible thanks to an extensible low level data loading architecture. New formats are added to the list regularly using this architecture, but users may also benefit from it and add support for their own formats in their applications. It is therefore possible to use Orekit in a system that already has some established mission-specific data formats.
Orekit also supports on-the-fly filtering of data during the loading process. Filtering can be used for example if data is stored on disk in compressed or enciphered form and should be uncompressed or deciphered at load time. Predefined filters readily available in Orekit allow to uncompress files using gzip (files ending in .gz), Unix compress (files ending in .Z), or Hatanaka method for RINEX files (files with a specific pattern, ending with either .##d where ## is a two-digits year for RINEX 2 files or .crx for RINEX 3 files).
Users may also benefit from the filtering architecture and add support for their own filters in their applications, for example to decipher sensitive data.
If some data format is not supported by Orekit, then a specialized DataLoader implementation can be set up by users.
The most important method in this class is the loadData method. This method takes as a parameter an already open InputStream from where data can be read using regular Java API. The second parameter is the name of the data file being loaded, it is only intended to generate meaningful error messages to end users if the file happens to be corrupted. The InputStream is already open and has already been passed through all applicable filters. This means that users only need to take care of the parsing itself, and their custom data loader will be automatically able to manage data coming from files, from the network, compressed or not as all these features have already been taken care of by the data providers and the data filters.
The way the data loaded is provided back to Orekit is not specified in the API. In fact, it depends on the data type. One recommended way to manage this is to create a dedicated container class for the data (ContainerWithNestedCustomParser in the following diagram) extending the AbstractSelfFeedingLoader class, and have a nested class Parser inside the container that implements DataLoader.
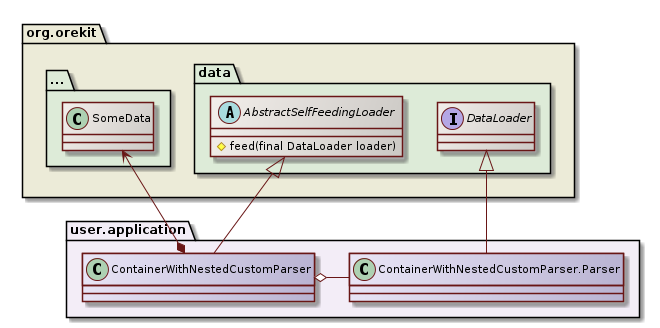
As the Parser is nested within the container, it can populate it while parsing. In order to have the nested parser being fed, a protected method feed in the AbstractSelfFeedingLoader is called internally with the Parser in argument, and this method will trigger the configured DataProvidersManager to feed itself. Users can look at the implementation of BulletinAFilesLoader to see how it works.
This can be used either to load data that is already known to Orekit (like EOP), but only the file format is unknown, or it can be used to load custom data.