
The Orekit library relies on some external data for physical models. Typical data are the Earth Orientation Parameters and the leap seconds history, both being provided by the IERS or the planetary ephemerides provided by JPL or IMCCE. Such data can be stored in text or binary files with specific formats that Orekit knows how to find and read, or can be stored in a database to which user application can connect. These data can also be completely embedded within an application built on top of Orekit.
One set of consistent data is referred to as a data context.
Regular standalone applications will use only one data context, i.e. one set of EOP, one set of JPL ephemerides, one history of leap seconds… But only one data context is not enough for some needs such as:
Orekit must be configured appropriately to select the proper context for each task.
Data that is only a few tens of kilobytes and can be assumed to never change like the constants for predefined precession-nutation models are already embedded in the core library, they are not associated with any data context. Small and simple data sets are defined by setting constants in the code itself. This is the case for the 32.184 seconds offset between Terrestrial Time and International Atomic Time scales for example. Large or complex fixed data are embedded by copying the corresponding resource files as is inside the compiled jar, under the assets directory. This is the case for the IAU-2000 precession-nutation model tables for example. There is nothing to configure for these fixed data sets as they are embedded within the library, so users may ignore them completely.
Other types of data sets correspond to either huge or changing data sets. These cannot realistically be embedded within a specific version of the library in the long run. A typical example for such data set is Earth Orientation Parameters which are mandatory for accurate frames conversions. Another example is planetary ephemerides. IERS regularly publishes new Earth Orientation Parameter files covering new time ranges whereas planetary ephemerides represent megabytes-sized files. These data sets must be provided by users through a data context and Orekit must be configured to find and load them at run time.
The following class diagram shows how contexts are handled in Orekit.
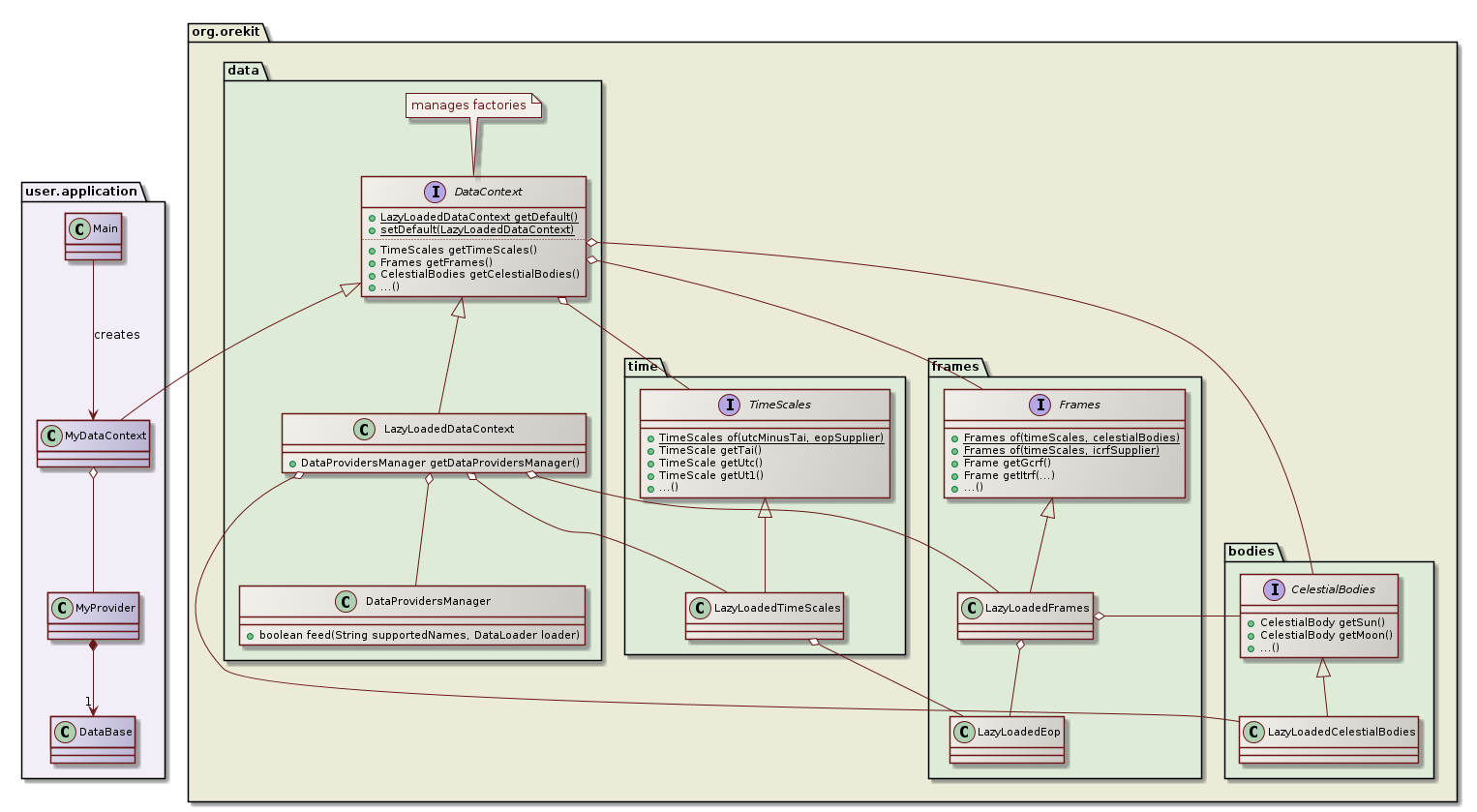
The top level interface is DataContext. It gathers links to all the factories Orekit uses to create the physical models that themselves require loading data. There is one factory for TimeScales that will need UTC-TAI history data for creating the UTC time scale, and EOP data for creating the UT1 time scale. There is one factory for frames that will need EOP data for Earth frame. There is one factory for celestial bodies that will need planetary ephemerides data for all bodies.
The DataContext interface has one implementation LazyLoadedDataContext that loads data on the fly from external resources (typically files) when first accessed and relies on a DataProvidersManager in order to find how to locate and parse these resources.
Users can provide their own implementation of DataContext, for example if all the data is stored in a mission-specific database, which would not fit with the resources or files-based LazyLoadedDataContext and DataProvidersManager.
Providing an implementation of DataContext consists in creating custom factories and setting up one class to get a single access point to all of them. The predefined LazyLoadedDataContext uses LazyLoadedTimeScales, LazyLoadedFrames, LazyLoadedEOP and LazyLoadedCelestialBodies for example, all of them relying on the same DataProvidersManager to seek and load data. In this implementation, some factories depend on other ones as one data context must provide consistent data. The EOP data for example is used by both LazyLoadedFrames (for Earth frames) and by LazyLoadedTimeScales (for UT1). The LazyLoadedFrames also depends on the CelestialBodies interface (for ICRF).
There are some static methods in the various factories (TimeScales.of(...), Frames.of(...) that create factories with preloaded constant data. These method are useful for users who need to implement their own data context.
An application that needs to use a specific data context must specify it. If the use is a direct reference to a context-dependent physical model (say the ITRF Earth frame), then a reference to the model is retrieved from the Frames factory that is associated with the desired context:
Frame itrf = myDataContext.getFrames().getITRF();
Sometimes, the reference is implicit and hidden within Orekit code. In this case, a default context is used. As an example, creating the builder for a Galileo specialized propagator with only the GalileoOrbitalElements will automatically retrieve both the EME2000 and the ITRF frames from a default context. If the default context is not the one the user wants to use, then the builder must be created by giving it explicitly the Frames factory to use. There are therefore many constructors and method that have two signatures, one with no DataContext nor factory, and one with either a DataContext or a factory and users must select the proper constructor/method to call depending on their needs.
This feature is mostly interesting for applications that need multiple contexts.
When an application needs to use a custom data context and avoid using the default data context there are a couple tools to help find where the default data context is used. First is a compiler plugin that detects when an application uses a method/constructor/field/class that has been annotated with @DefaultDataContext from a method/constructor/field/class that does not have that annotation. All methods, constructors, and fields in Orekit that use the default data context have the annotation. This annotation and plugin operates similarly to the @Deprecated annotation. It will find all uses that are known at compile time. To use the plugin add -Xplugin:dataContextPlugin to the javac command line arguments. For example, here is a snippet from a pom.xml that uses the compiler plugin:
<project>
...
<dependencies>
<dependency>
<groupId>org.orekit</groupId>
<artifactId>orekit</artifactId>
<version>10.1</version>
<scope>compile</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<showWarnings>true</showWarnings>
<compilerArgs>
<arg>-Xplugin:dataContextPlugin</arg>
</compilerArgs>
</configuration>
</plugin>
</plugins>
</build>
</project>
The compiler plugin can detect uses of the default data context that are known at compile time, but it is unable to detect polymorphic uses of the default data context. For example the plugin will detect that Object o = AbsoluteDate.J2000_EPOCH; uses the default data context, but not o.toString();. To detect the latter types a runtime tool is needed.
The second tool for detecting uses of the default data context is ExceptionalDataContext. This is a DataContext that simply throws an exception whenever one of its methods is called. This can be used when running tests to ensure that none of the tested code accesses the default data context. Because some static fields in Orekit are initialized using the default data context those classes must be initialized before replacing the default data context. To use ExceptionalDataContext run the following code before any other code that uses Orekit:
// Force initialization of classes with static fields that use the default data context Object o = AbsoluteDate.ARBITRARY_DATE; o = InertialProvider.EME2000_ALIGNED; // Prevent further use of the default data context DataContext.setDefault(new ExceptionalDataContext());
ExceptionalDataContext is unable to detect uses of static fields that use the default data context, such as those in AbsoluteDate and InertialProvider. Using both the compiler plugin and ExceptionalDataContext together will be able to detect all uses of the default data context. This provides a way to verify that the correct instance of an overloaded constructor or method is called so as to avoid any surprise uses of the default data context.