
The org.orekit.files.ccsds package provides classes to handle parsing and writing CCSDS messages.
The package is organized in hierarchical sub-packages that reflect the sections hierarchy from CCSDS messages, plus some utility sub-packages. The following class diagram depicts this static organization.
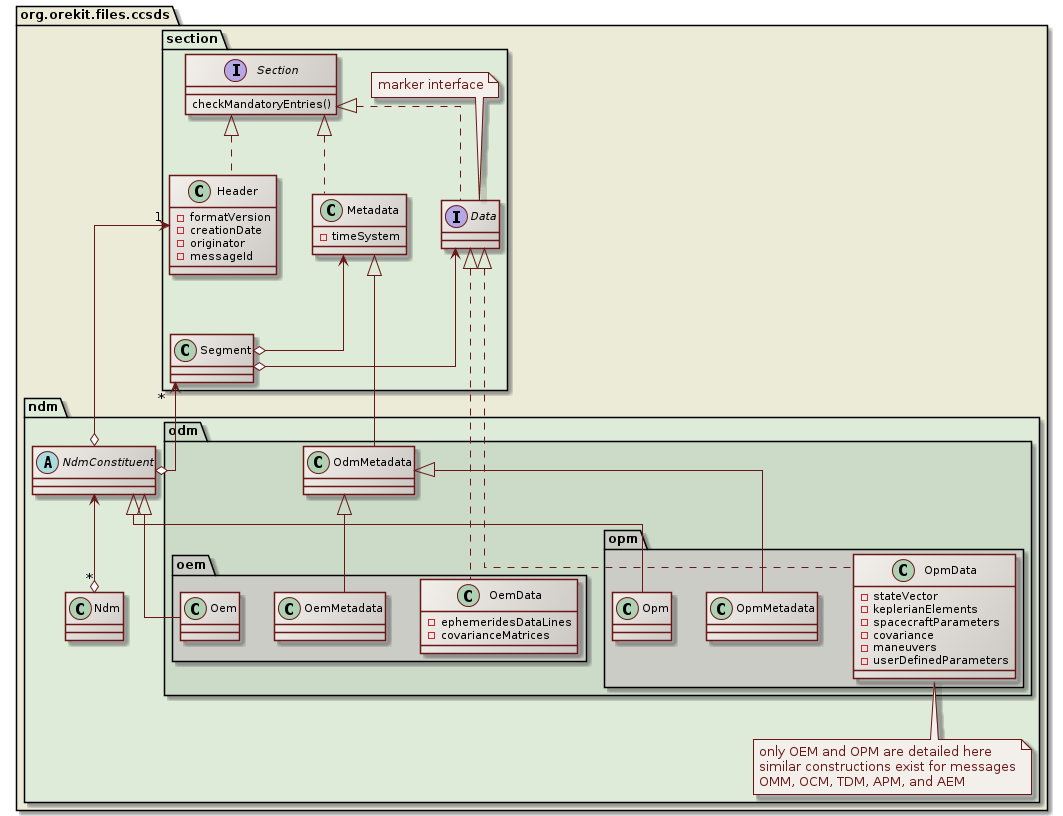
The org.orekit.files.ccsds.section sub-package defines the generic sections found in all CCSDS messages: Header, Metadata and Data. All extends the Orekit-specific Section interface that is used for checks at the end of parsing. Metadata and Data are gathered together in a Segment structure.
The org.orekit.files.ccsds.ndm sub-package defines a single top-level abstract class Ndm, which stands for Navigation Data Message. All CCDSD messages extend this top-level abstract class. Ndm is a container for one Header and one or more Segment objects, depending on the message type (for example Opm only contains one segment whereas Oem may contain several segments).
There are as many sub-packages as there are CCSDS message types, with intermediate sub-packages for each officially published recommendation: org.orekit.files.ccsds.ndm.adm.apm, org.orekit.files.ccsds.ndm.adm.aem, org.orekit.files.ccsds.ndm.odm.opm, org.orekit.files.ccsds.ndm.odm.oem, org.orekit.files.ccsds.ndm.odm.omm, org.orekit.files.ccsds.ndm.odm.ocm, and org.orekit.files.ccsds.ndm.tdm. Each contain the logical structures that correspond to the message type, among which at least one ##m class that represents a complete message. As some data are common to several types, there may be some intermediate classes in order to avoid code duplication. These classes are implementation details and not displayed in the previous class diagram. If the message type has logical blocks (like state vector block, Keplerian elements block, maneuvers block in OPM), then there is one dedicated class for each logical block.
The top-level message also contains some Orekit-specific data that are mandatory for building some objects but are not present in the CCSDS messages. This includes for example IERS conventions, data context, and gravitational coefficient for ODM as it is sometimes optional in these messages.
This organization has been introduced with Orekit 11.0. Before that, the CCSDS hierarchy with header, segment, metadata and data was not reproduced in the API but a flat structure was used.
This organization implies that users wishing to access raw internal entries must walk through the hierarchy. For message types that allow only one segment, there are shortcuts to use message.getMetadata() and message.getData() in addtion to message.getSegments().get(0).getMetadata() and message.getSegments().get(0).getData() respectively. Where it is relevant, other shortcuts are provided to access Orekit-compatible objects as shown in the following code snippet:
Opm opm = ...; AbsoluteDate creationDate = opm.getHeader().getCreationDate(); Vector3D dV = opm.getManeuver(0).getdV(); SpacecraftState state = opm.generateSpacecraftState(); // getting orbit date the hard way: AbsoluteDate orbitDate = opm.getSegments().get(0).get(Data).getStateVectorBlock().getEpoch();
Messages can be obtained by parsing an existing message or by using the setters to create them from scratch, bottom up starting from the raw elements and building up through logical blocks, data, metadata, segments, header and finally message.
Parsing a text message to build some kind of Ndm object is performed by setting up a parser. Each message type has its own parser, but a single ParserBuilder can build all parsers type. Once created, the parser parseMessage method is called with a data source. It will return the parsed message as a hierarchical container as depicted in the previous section.
The Orekit-specific data that are mandatory for building some objects but are not present in the CCSDS messages are set up beforehand when building the ParserBuilder. This includes for example IERS conventions, data context, and gravitational coefficient for ODM as it is sometimes optional in these messages.
The ParsedUnitsBehavior setting in ParseBuilder is used to select how units found in the messages at parse time should be handled with respect to the mandatory units specified in CCSDS standards.
IGNORE_PARSE means that the units parsed in the message are completely ignored, numerical values are interpreted using the units specified in the standardCONVERT_COMPATIBLE means that units parsed in the message are checked for dimension compatibility with respect to the standard, and accepted if conversion is possibleSTRICT_COMPLIANCE means that units parsed in the message are checked for dimension compatibility with respect to the standard, and accepted only if they are equalsCCSDS standards are ambiguous with respect to units handling. In several places, they state that units are “for information purpose only” or even that “listing of units via the [insert keyword here] keyword does not override the mandatory units specified in the selected [insert type here]”. This would mean that IGNORE_PARSE should be used for compliance with the standard and messages specifying wrong units should be accepted silently. Other places state that the tables specify “the units to be used” and that “If units are displayed, they must exactly match the units (including lower/upper case) as specified in tables”. This would mean that STRICT_COMPLIANCE should be used for compliance with the standard and messages specifying wrong units should be rejected with an error message. Best practices in general file parsing are to be lenient while parsing and strict when writing. As it seems logical to consider that when a message explicitly states units, these are the units that were really used for producing the message, we consider that CONVERT_COMPATIBLE is a good trade-off for leniency. The default setting is therefore to set the ParseBuilder behavior to CONVERT_COMPATIBLE, but users can configure their builder differently to suit their needs. The units parser used in Orekit is also feature-rich and knows how to handle units written with human-friendly unicode characters, like for example km/s² or √km (whereas CCSDS standard would use km/s**2 or km**0.5).
One change introduced in Orekit 11.0 is that the progressive set up of parsers using the fluent API (methods withXxx()) has been moved to the top-level ParserBuilder that can build the parsers for all CCSDS messages. Another change is that the parsers are mutable objects that gather the data during the parsing. They can therefore not be used in multi-threaded environment. The recommended way to use parsers is then to set up one ParserBuilder and to call its buildXymParser() methods from within each thread to dedicate one parser for each message and drop it afterwards. In single-threaded cases, parsers used from within a loop can be reused safely after the parseMethod has returned, but building a new parser from the builder is simple and has little overhead, so asking the existing ParseBuilder to build a new parser for each message is still the recommended way in single-threaded applications.
Parsers automatically recognize if the message is in Key-Value Notation (KVN) or in eXtended Markup Language (XML) format and adapt accordingly. This is transparent for users and works with all CCSDS message types.
The data to be parsed is provided using a DataSource object, which combines a name and a stream opener and can be built directly from these elements, from a file name, or from a standard Java File instance. The DataSource object delays the real opening of the file until the parseMessage method is called and takes care to close it properly after parsing, even if parsing is interrupted due to some parse error.
The OemParser and OcmParser have an additional feature: they also implement the generic EphemerisFileParser interface, so they can be used in a more general way when ephemerides can be read from various formats (CCSDS, CPF, SP3). The EphemerisFileParser interface defines a parse(dataSource) method that is similar to the CCSDS-specific parseMessage(dataSource) method.
As the parsers are parameterized with the type of the parsed message, the parseMessage and parse methods in all parsers already return an object with the proper specific message type. There is no need to cast the returned value as was done in pre-11.0 versions of Orekit.
The following code snippet shows how to parse an OEM, in this case using a file name to create the data source, and using the default values for the parser builder:
Oem oem = new ParserBuilder().buildOemParser().parseMessage(new DataSource(fileName));
Writing a CCSDS message is done by using a specific writer class for the message type and using a low level generator corresponding to the desired message format, KvnGenerator for Key-Value Notation or XmlGenerator for eXtended Markup Language.
All CCSDS messages have a corresponding writer that implements the CCSDS-specific MessageWriter interface. This interface allows to write either an already built message, or separately the header first and then looping to write the segments.
Ephemeris-type messages (AEM, OEM and OCM) also implement the generic ephemeris writer interfaces (AttitudeEphemerisFileWriter and EphemerisFileWriter) in addition to the CCSDS-specific interface, so they can be used in a more general way when ephemerides data is built from non-CCSDS data. The generic write methods in these interfaces take as arguments objects that implement the generic AttitudeEphemerisFile.AttitudeEphemerisSegment and EphemerisFile.EphemerisSegment interfaces. As these interfaces do not provide access to header and metadata informations that CCSDS writers need, these informations must be provided beforehand to the writers. This is done by providing directly the header and a metadata template in the constructor of the writer. Of course, writers for non-CCSDS message formats would use different strategies to get their specific metadata. In the CCCSDS case, the metadata provided is only a template that is incomplete: the frame, start time and stop time will be filled later on when the data to be written is available, as they will change for each segment. The argument used as the template is not modified when building a writer, its content is copied in an internal object that is modified by adding the proper frame and time data when each segment is created.
Ephemeris-type messages can also be used in a streaming way (with specific Streaming##MWriter classes) if the ephemeris data must be written as it is produced on-the-fly by a propagator. These specific writers provide a newSegment() method that returns a fixed step handler to register to the propagator. If ephemerides must be split into different segments, in order to prevent interpolation between two time ranges separated by a discrete event like a maneuver, then a new step handler must be retrieved using the newSegment() method at discrete event time and a new propagator must be used (or propagator.getMultiplexer().remove(oldSegmentHandler) and propagator.getMultiplexer().add(newSegmentHandler) must be called appropriately). All segments will be gathered properly in the generated CCSDS message. Using the same propagator and same event handler would not work as expected: the propagator would run just fine through the discrete event that would reset the state, but the ephemeris would not be aware of the change and would just continue the same segment. Upon reading the message produced this way, the reader would not be aware that interpolation should not be used around this maneuver as the event would not appear in the message.
In accordance with file handling best practices, when writing CCSDS messages, Orekit complies strictly to the units specified in the standard. If the low level generator is configured to write units (writing units is optional), then the units will be standard ones, and the syntax will be the CCSDS syntax. For better compliance and compatibility with other systems, this choice cannot be customized, it is enforced by the library.
This section describes the design of the CCSDS framework. It is an implementation detail and is useful only for Orekit developers or people wishing to extend it, perhaps by adding support for new messages types. It is not required to simply parse or write CCSDS messages.
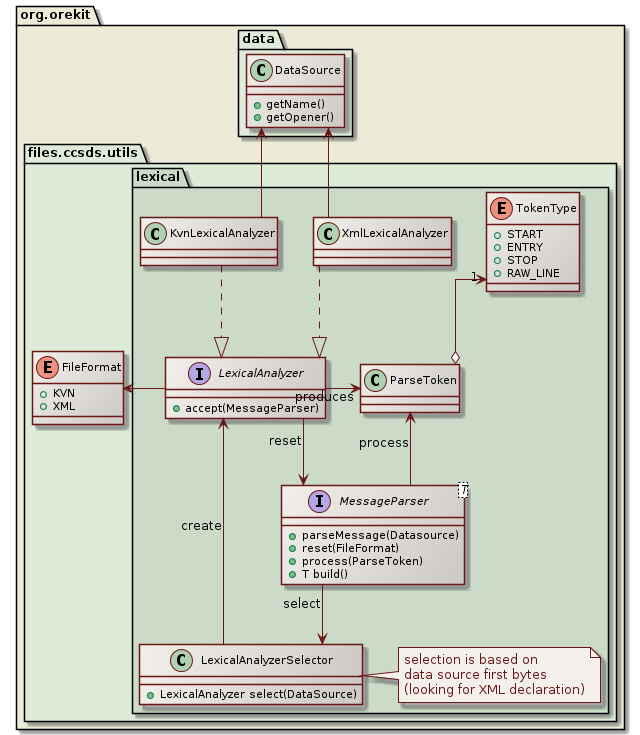
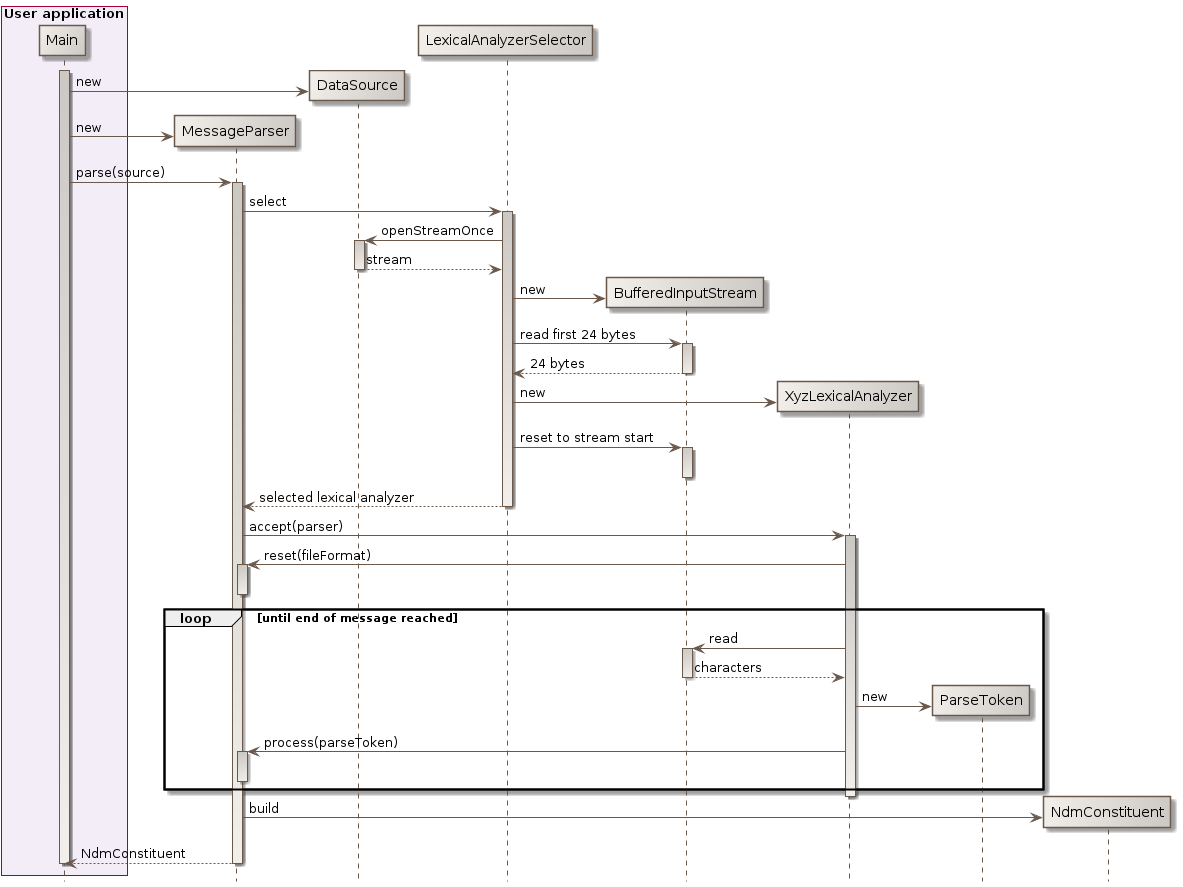
The first level of parsing is lexical analysis. Its aim is to read the stream of characters from the data source and to generate a stream of ParseToken. Two different lexical analyzers are provided: KvnLexicalAnalyzer for Key-Value Notation and XmlLexicalAnalyzer for eXtended Markup Language. The LexicalAnalyzerSelector utility class selects one or the other of these lexical analyzers depending on the first few bytes read from the data source. If the start of the XML declaration (“<?xml …>”) is found, then XmlLexicalAnalyzer is selected, otherwise KvnLexicalAnalyzer is selected. Detection works for UCS-4, UTF-16 and UTF-8 encodings, with or without a Byte Order Mark, and regardless of endianness. This XML declaration is optional in general-purpose XML documents (at least for XML 1.0) but CCSDS messages and XML 1.1 specification both require it to be present. After the first few bytes allowing selection have been read, the characters stream is reset to beginning so the selected lexical analyzer will see these characters again. This works even if the DataSource is a network stream, thanks to some internal buffering. Once the lexical analyzer has been created, the message parser registers itself to this analyzer by calling its accept method, and wait for the lexical analyzer to call it back for processing the tokens it will generate from the characters stream. This is akin to the visitor design pattern with the parser visiting the tokens as they are produced by the lexical analyzer.
The following class diagram presents the static structure of lexical analysis:
The dynamic view of lexical analysis is depicted in the following sequence diagram:
The second level of parsing in message parsing is semantic analysis. Its aim is to read the stream of ParseToken objects and to progressively build the CCSDS message from them. Semantic analysis of primitive entries like EPOCH_TZERO = 1998-12-18T14:28:15.1172 in KVN or <EPOCH_TZERO>1998-12-18T14:28:15.1172</EPOCH_TZERO> in XML is independent of the message format: both lexical analyzers will generate a ParseToken with type set to TokenType.ENTRY, name set to EPOCH_TZERO and content set to 1998-12-18T14:28:15.1172. This token will be passed to the message parser for processing and the parser may ignore that the token was extracted from a KVN or a XML message. This simplifies a lot parsing of both formats and avoids code duplication. This is unfortunately not true anymore for higher level structures like header, segments, metadata, data or logical blocks. For all these cases, the parser must know if the message is in Key-Value Notation or in eXtended Markup Language. The lexical analyzer therefore starts parsing by calling the parser reset method with the message format as an argument, so the parser is aware of the format and knows how to handle the higher level structures.
CCSDS messages are complex, with a lot of sub-structures and we want to parse several types (APM, AEM, OPM, OEM, OMM, OCM and TDM as of version 11.0). There are hundreds of keys to manage (i.e. a lot of different names a ParseToken can have). Prior to version 11.0, Orekit used a single big enumerate class for all these keys, but it proved unmanageable as more message types were supported. The framework set up with version 11.0 is based on the fact these numerous keys belong to a smaller set of logical blocks that are always parsed as a whole (header, metadata, state vector, covariance…). Parsing is therefore performed with the parser switching between a small number of well-known states. When one state is active, say metadata parsing, then lookup is limited to the keys allowed in metadata. If an unknown token arrives, then the parser assumes the current section is finished, and it switches into another state that was declared as the fallback to use after metadata. In this case, it may be a state dedicated to data parsing. This is an implementation of the State design pattern. Parsers always have one current ProcessingState that remains active as long as it can process the tokens provided to it by the lexical analyzer, and they have a fallback ProcessingState to switch to when a token could not be handled by the current one. The following class diagram shows this design:
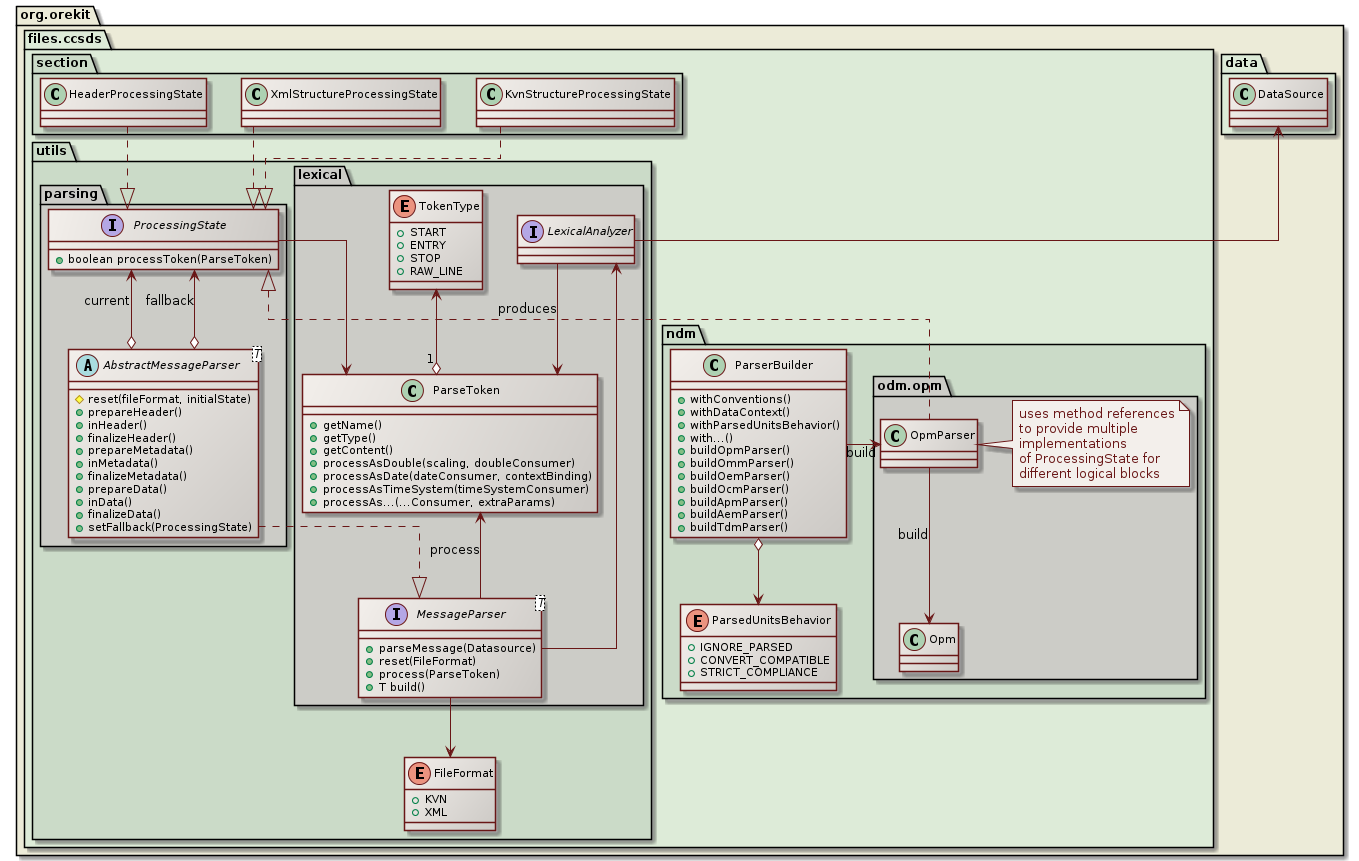
All parsers set up the initial processing state when their reset method is called by the lexical analyzer at the beginning of the message, and they manage the fallback processing state by anticipating what the next state could be when one state is activated. This is highly specific for each message type, and unfortunately also depends on message format (KVN vs. XML). As an example, in KVN messages, the initial processing state is HeaderProcessingState, but in XML messages it is rather XmlStructureProcessingState and HeaderProcessingState is triggered only when the XML <header> start element is processed. CCSDS messages type are also not very consistent, which makes implementation more complex. As an example, APM don’t have META_START, META_STOP, DATA_START or DATA_STOP keys in the KVN version, whereas AEM have both, and OEM have META_START, META_STOP but have neither DATA_START nor DATA_STOP. All parsers extend the AbstractMessageParser abstract class from which declares several hooks (prepareHeader, inHeader, finalizeHeader, prepareMetadata…) which can be called by various states so the parser keeps track of where it is and prepares the fallback processing state accordingly. The prepareMetadata hook for example is called by KvnStructureProcessingState when it sees a META_START key, and by XmlStructureProcessingState when it sees a metadata start element. The parser then knows that metadata parsing is going to start an set up the fallback state for it. Unfortunately, as APM in KVN format don’t have a META_START key, prepareMetadata will not be called automatically so the parse itself must take care of it by itself (it does it when the first metadata token is detected).
When the parser is not switching states, one state is active and processes all upcoming tokens one after the other. Each processing state may adopt a different strategy for this, depending on the section it handles. Processing states are always quite small. Some processing states that can be reused from message type to message type (like HeaderProcessingState, KvnStructureProcessingState or XmlStructureProcessingstate) and are implemented as separate classes. Other processing states that are specific to one message type (and hence to one parser), are implemented as a single private method within the parser. Method references are used to point directly to these methods. This allows one parser class to provide simultaneously several implementations of the ProcessingState interface. The following example is extracted from the TdmParser, it shows that when a DATA_START key is seen in a KVN message or when a <data> start element is seen in an XML message, then prepareData is called and an ObservationsBlock is allocated to hold the upcoming observations. Then the fallback processing state is set to the private method processDataToken so that the next token, which at this stage is expected to be a data token representing an observation, can be processed properly:
public boolean prepareData() {
observationsBlock = new ObservationsBlock();
setFallback(this::processDataToken);
return true;
}
In most cases, the keys that are allowed in a section are fixed so they are defined in an enumerate. The processing state (in this case often a private method within the parser) then simply selects the constant corresponding to the token name using the standard valueOf method from the enumerate class and delegates to it the processing of the token content. The enum constant usually just calls one of the processAs method from the token, pointing it to the metadata/data/logical block setter to call for storing the token content. For sections that both reuse some keys from a more general section and add their own keys, several enumerate types can be checked in row. A typical example of this design is the processMetadataToken method in OemParser, which is a single private method acting as a ProcessingState and tries the enumerates MetadataKey, OdmMetadataKey, CommonMetadataKey and finally OemMetadataKey to fill up the metadata section. There are a few cases when this design using an enumerate does not work, for example with user-defined data and keywords. In such cases an ad-hoc implementation is used.
Adding a new message type (lets name it XYZ message) involves:
Xyz class that extends Ndm,XyzData container for the data part,XyzSection1Key, XyzSection2Key… enumerates for each logical blocks that are allowed in the message formatXyzParserbuildXyzParser method in ParserBuilderXyzWriter class.In the list above, creating the XyzParser is probably the most time-consuming task. In this new parser, one has to set up the state switching logic, using existing classes for the global structure and header, and private methods processSection1Token, processSection2Token… for processing the tokens from each logical block.
Adding a new key to an existing message when a new version of the message format is published by CCSDS generally consists in adding one field in the data container with a setter and a getter, and one enum constant that will be recognized by the existing processing state and that will call one of the processAs method from the token, asking it to call the new setter.
The following class diagram presents the implementation of writing:
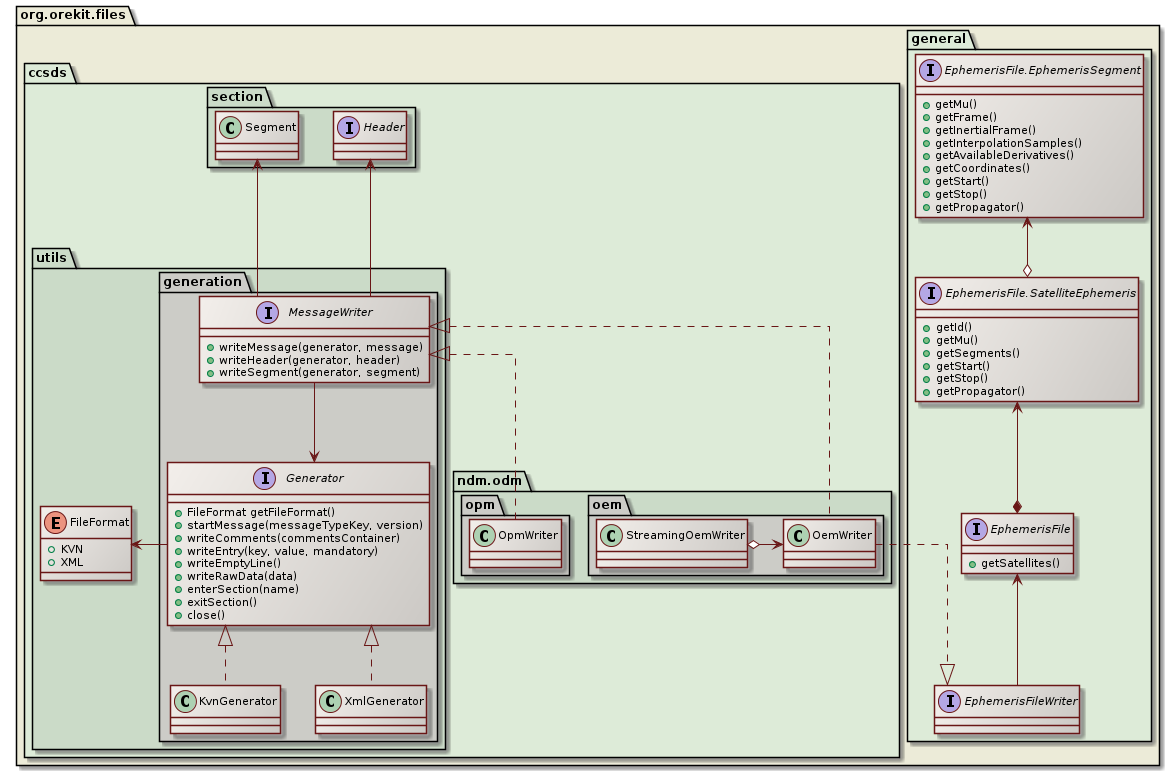
In this diagram, only OpmWriter and OemWriter are shown, but other writers exist for the remaining formats, with similar structures.
When the top level writers are built, they are configured with references to header and metadata containers. This is what allows OemWriter to implement EphemerisFileWriter and thus to be able to write any ephemeris as an OEM, even if the ephemeris itself has none of the CCSDS specific metadata and header. The ephemeris can be created from scratch using a propagator, and it can even be written on the fly as it is computed, if one embeds an OemWriter in a StreamingOemWriter.
The writers do not write the data by themselves, they delegate it to some implementation of the Generator interface, which is the counterpart of the LexicalAnalyzer seen in the parsing section. There are two implementations of Generator, one generating Key-Value Notation and the other one generating eXtended Markup Language (XML).