Hello everyone,
Today is the start of June and thus the start of my contribution through SOCIS on Orekit!
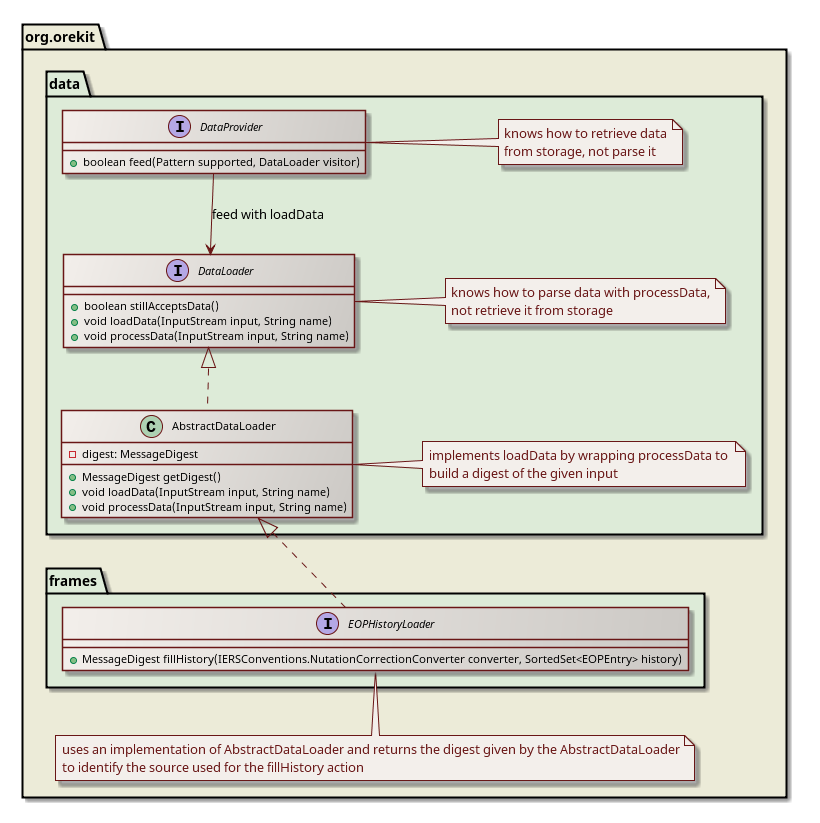
My current proposal towards Database support is an extension of the current API to incorporate a message digest of the inputstreams that are used to parse data. This digest (simple SHA-1 hash) will be used to identify the source of the data and will be stored with the data in the database.
I would prefer a design shown in the attached diagram for this, if this design is not to intrusive then I propose that I'll make a draft of the database storage application using the design shown in my original proposal and see how it goes.
If the sources of data are not important towards the correctness of the data (e.g. we don't have to warn users of the database application that (1) the file is already used to load the data or (2) an entry has already been added from a different source) then we can drop this functionality and move on with the database storage.
I have mentioned this before in my proposal but what is the preferred persistence API? In my opinion, JPA is most accessible and known to Java developers. There is however a large group of developers that dislike the ORM approach.
---------
With the feature discussion out of the way I would also like to ask some practical questions. As you have noticed by now this e-mail has gotten rather large. I'm a fan of reporting very frequently and would like to continue to do this. What kind of schedule would the Orekit developers prefer (weekly, bi-weekly, daily) and where should I report (mailing list, forge documents/wiki)?
Thanks!
Bob
{kind=link}